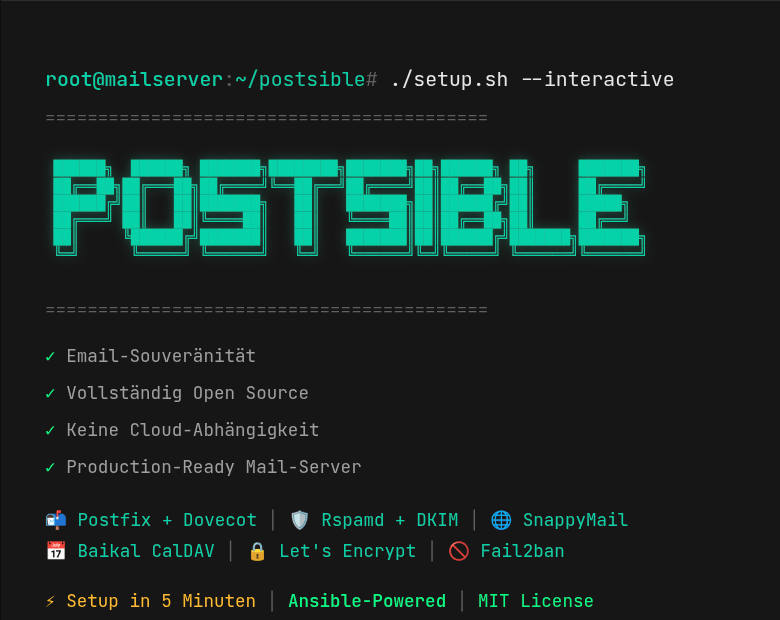
Postsible: Warum ich meinen eigenen Mail-Server gebaut habe
Ein Mail-Server-Setup das nicht nervt — weil alle anderen Lösungen nervig waren „Wie schwer kann es schon sein, einen Mail-Server aufzusetzen?“ — Berühmte letzte Worte, bevor man drei Tage lang Postfix-Konfigurationen debuggt. Spoiler: Es ist… Weiterlesen »Postsible: Warum ich meinen eigenen Mail-Server gebaut habe